Voice Stack ของ Microsoft: MAI-Voice-1 + MAI-Transcribe-1 มีความหมายอย่างไรต่อสรุปพอดแคสต์ BibiGPT
Voice Stack ของ Microsoft: MAI-Voice-1 + MAI-Transcribe-1 มีความหมายอย่างไรต่อสรุปพอดแคสต์ BibiGPT
สารบัญ
- MAI-Transcribe-1 คืออะไร และเหตุใดจึงสำคัญต่อการถอดเสียงพอดแคสต์ด้วย AI?
- MAI-Voice-1: เสียง 60 วินาทีใน 1 วินาที
- MAI-Transcribe-1 vs Whisper / Voxtral: ความต่างสำคัญสามประการ
- ความหมายต่อผู้ใช้ BibiGPT: ฐานสรุปพอดแคสต์ที่แข็งแกร่งขึ้น
- BibiGPT วางแผนอยู่ร่วมกับซีรีส์ MAI อย่างไร
- FAQ
- สรุป
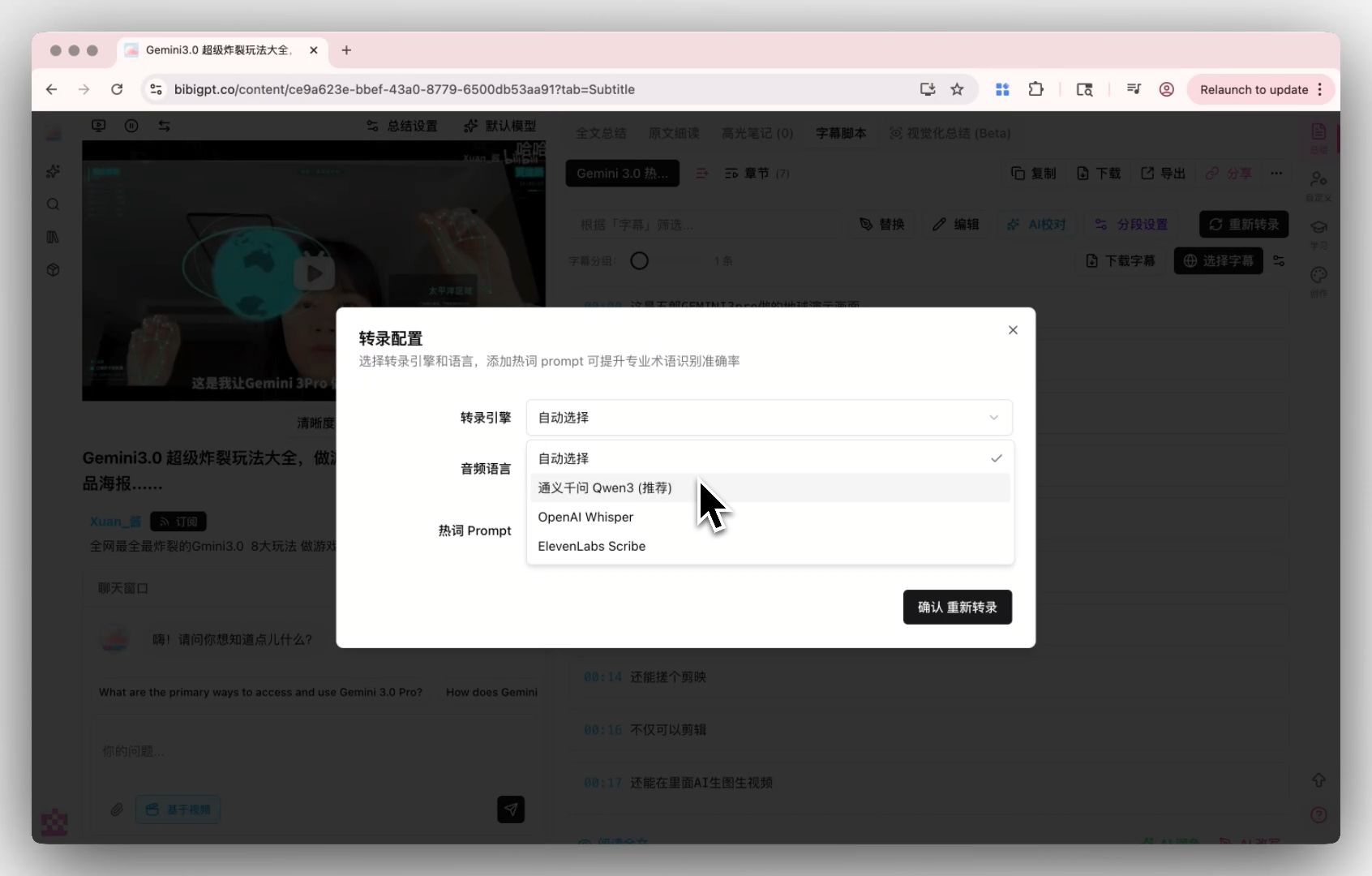
MAI-Transcribe-1 คืออะไร และเหตุใดจึงสำคัญต่อการถอดเสียงพอดแคสต์ด้วย AI?
คำตอบสั้น: MAI-Transcribe-1 คือโมเดล ASR (automatic speech recognition) ในเครือของ Microsoft ประกาศในเดือนเมษายน 2026 พร้อมกับ MAI-Voice-1 ผลกระทบทันทีต่อการถอดเสียงพอดแคสต์ด้วย AI คือ word error rate (WER) ที่ต่ำลงในสถานการณ์หลายภาษาและมีเสียงรบกวน พร้อมต้นทุน inference ที่ลดลง — ทำให้เครื่องมือปลายทางอย่าง เครื่องสรุปพอดแคสต์ AI สามารถสร้างจาก transcript ที่แม่นยำกว่าด้วยต้นทุนที่ต่ำลง
ในวันที่ 2 เมษายน 2026 ทีม MAI (Microsoft AI) เปิดตัวโมเดลเสียงในเครือสองตัวพร้อมกัน:
- MAI-Voice-1 — text-to-speech (TTS) เสียง 60 วินาทีใน 1 วินาทีบน GPU เดียว
- MAI-Transcribe-1 — automatic speech recognition (ASR) สร้าง SOTA ใหม่บน benchmark หลายภาษาด้วย latency ที่ต่ำลงอย่างชัดเจน
นี่คือครั้งแรกที่ Microsoft เปลี่ยน ทั้งสองด้าน ของ voice stack ไปใช้โมเดลในเครือแทนที่จะพึ่ง OpenAI Whisper หรือ TTS ของบุคคลที่สาม สัญญาณชัดเจน: โมเดลเสียงพื้นฐานกำลังเข้าสู่ยุค “first-party + low-latency end-to-end” และเสียงยาว (พอดแคสต์ การสัมภาษณ์ การประชุม) จะได้ประโยชน์มากที่สุด
MAI-Voice-1: เสียง 60 วินาทีใน 1 วินาที
คำตอบสั้น: MAI-Voice-1 คือโมเดล TTS ในเครือของ Microsoft Microsoft อ้างว่าเสียง 60 วินาทีใน 1 วินาทีบน GPU เดียว — เป็นหนึ่งในโมเดล TTS ที่เร็วที่สุดในการใช้งานจริง ใช้งานอยู่แล้วใน Copilot Daily / Podcasts มีนัยชัดเจนต่อ assistant แบบเรียลไทม์ การพากย์ low-latency และการบรรยายข้อความยาว
จุดเด่น:
- เร็วกว่าเรียลไทม์ 60 เท่า: ข้อความ 60 วินาที → เสียง 1 วินาที เหมาะสำหรับการบรรยายเนื้อหายาว
- ทำงานบน GPU เดียว ต่างจากระบบ TTS หลายตัวที่ต้องใช้คลัสเตอร์
- ใช้งานจริงแล้ว ใน Copilot Daily News และ workflow Podcasts
นัยต่อสถานการณ์ “สรุปเสียงวิดีโอยาว → พอดแคสต์” อย่าง BibiGPT: ทั้งฝั่งอินพุต (การถอดเสียงพอดแคสต์) และฝั่งเอาต์พุต (การสร้างเสียง “พอดแคสต์สองพิธีกร”) ตอนนี้สามารถทำงานด้วย latency ที่ต่ำลงมาก การสร้างพอดแคสต์ ของ BibiGPT แปลงวิดีโอใดๆ เป็นการสนทนาสองพิธีกรอยู่แล้ว เมื่อ TTS เร็วอย่าง MAI-Voice-1 พัฒนาเต็มที่ “สรุปพร้อมบรรยาย” จะเป็นไปได้แบบเรียลไทม์
MAI-Transcribe-1 vs Whisper / Voxtral: ความต่างสำคัญสามประการ
คำตอบสั้น: เทียบกับ OpenAI Whisper-v3 และ Mistral Voxtral แล้ว MAI-Transcribe-1 โดดเด่นในสามมิติ: WER ที่ต่ำกว่า (โดยเฉพาะในสภาพแวดล้อมที่มีเสียงรบกวนและคำศัพท์เฉพาะทาง), inference ที่เร็วกว่า, และการรวมเข้ากับ Azure / Copilot อย่างแน่นแฟ้น ระยะสั้น Whisper ยังเป็นค่า default open-source ส่วน MAI-Transcribe-1 จะกลายเป็น benchmark ใหม่ของ commercial API
| มิติ | MAI-Transcribe-1 | OpenAI Whisper-v3 | Mistral Voxtral |
|---|---|---|---|
| Open source | ไม่ (commercial API) | ใช่ (MIT) | ใช่ (Apache 2.0) |
| หลายภาษา | 25+ ภาษา CJK เสถียร | 99 ภาษา อ่อนใน long-tail | EN + เน้น EU |
| เสียงยาว | บริบท native 60+ นาที | ต้องแบ่งเป็น chunk | รองรับ context ยาว |
| Latency | ต่ำกว่า Whisper อย่างมีนัยสำคัญ | ปานกลาง | เร็ว |
| การ Deploy | Hosted บน Azure | Self-host หรือ cloud | Self-host open source |
| ราคา | ต่อนาที | Open source (จ่ายค่า GPU) | Open source |
ตาม บล็อกของ Microsoft AI ซีรีส์ MAI มีไว้เพื่อรวม voice stack ทั่วทั้ง full-stack AI ของ Microsoft (Search, Copilot, Office, Gaming, Bing) บนเทคโนโลยีในเครือ สำหรับแอปปลายทาง นั่นแปลว่า SLA ที่เสถียรกว่าและ versioning ของโมเดลที่ชัดเจนกว่า
สำหรับผลิตภัณฑ์อย่าง BibiGPT — ที่ไม่ได้ผูกกับโมเดลเสียงเดียว — MAI-Transcribe-1 เป็นอีกหนึ่งตัวเลือกใน pool ของ custom transcription engine ไม่ใช่การมาแทนที่
ความหมายต่อผู้ใช้ BibiGPT: ฐานสรุปพอดแคสต์ที่แข็งแกร่งขึ้น
คำตอบสั้น: สามชัยชนะที่จับต้องได้สำหรับผู้ใช้ BibiGPT — การถอดเสียงที่แม่นยำขึ้นสำหรับพอดแคสต์และเสียงยาว, workflow แปลซับไตเติล หลายภาษาที่ราบรื่นขึ้น, และ pool custom transcription engines ที่หลากหลายกว่าเดิมให้เลือก
กรณีที่ 1: เสียงพอดแคสต์ / การสัมภาษณ์ความยาว
เสียงยาว (>30 นาที) คือจุดอ่อนของ Whisper — การแบ่ง chunk ทำให้สูญเสียบริบท การรองรับ context ยาวแบบ native ของ MAI-Transcribe-1 หมายความว่าพอดแคสต์ Spotify และการสัมภาษณ์ในวงการจะถอดเสียงได้สะอาดกว่า ดู คู่มือ workflow สรุปพอดแคสต์ด้วย AI เพื่อเปรียบเทียบ
กรณีที่ 2: เนื้อหาหลายภาษาข้ามพรมแดน
ข่าวข้ามภูมิภาค การสัมภาษณ์ JP / KR การประชุมสองภาษา EN-CN — WER หลายภาษาของ MAI เสถียรกว่าในสถานการณ์ผสม สำหรับครีเอเตอร์ที่จะ go global หรือนักวิจัยข้ามพรมแดน chain แปลอัตโนมัติเมื่ออัปโหลด (recognize → translate) ได้ฐาน ASR ที่แม่นยำขึ้น
กรณีที่ 3: เนื้อหาเฉพาะทางที่หนาแน่นด้วยศัพท์
การแพทย์ กฎหมาย การเงิน เทคนิค — ศัพท์เฉพาะทางหนาแน่นมักพึ่งเอนจินผู้เชี่ยวชาญอย่าง ElevenLabs Scribe การเพิ่ม MAI-Transcribe-1 ขยาย pool ทำให้ผู้ใช้เลือกความสมดุลระหว่างราคา / ความแม่นยำ / ภาษาที่เหมาะกับเนื้อหามากที่สุด
BibiGPT วางแผนอยู่ร่วมกับซีรีส์ MAI อย่างไร
คำตอบสั้น: BibiGPT ไม่เคยมีจุดยืนที่จะเดิมพันกับโมเดลเสียงตัวเดียว MAI-Voice-1 / Transcribe-1 ทำให้ flow หลักของ BibiGPT (transcribe → summarize → mind map → article / podcast) ทำงานบนฐานที่แข็งแกร่งขึ้น
เส้นทางความเข้ากันได้: เสียบ MAI-Transcribe-1 เข้า custom transcription engine
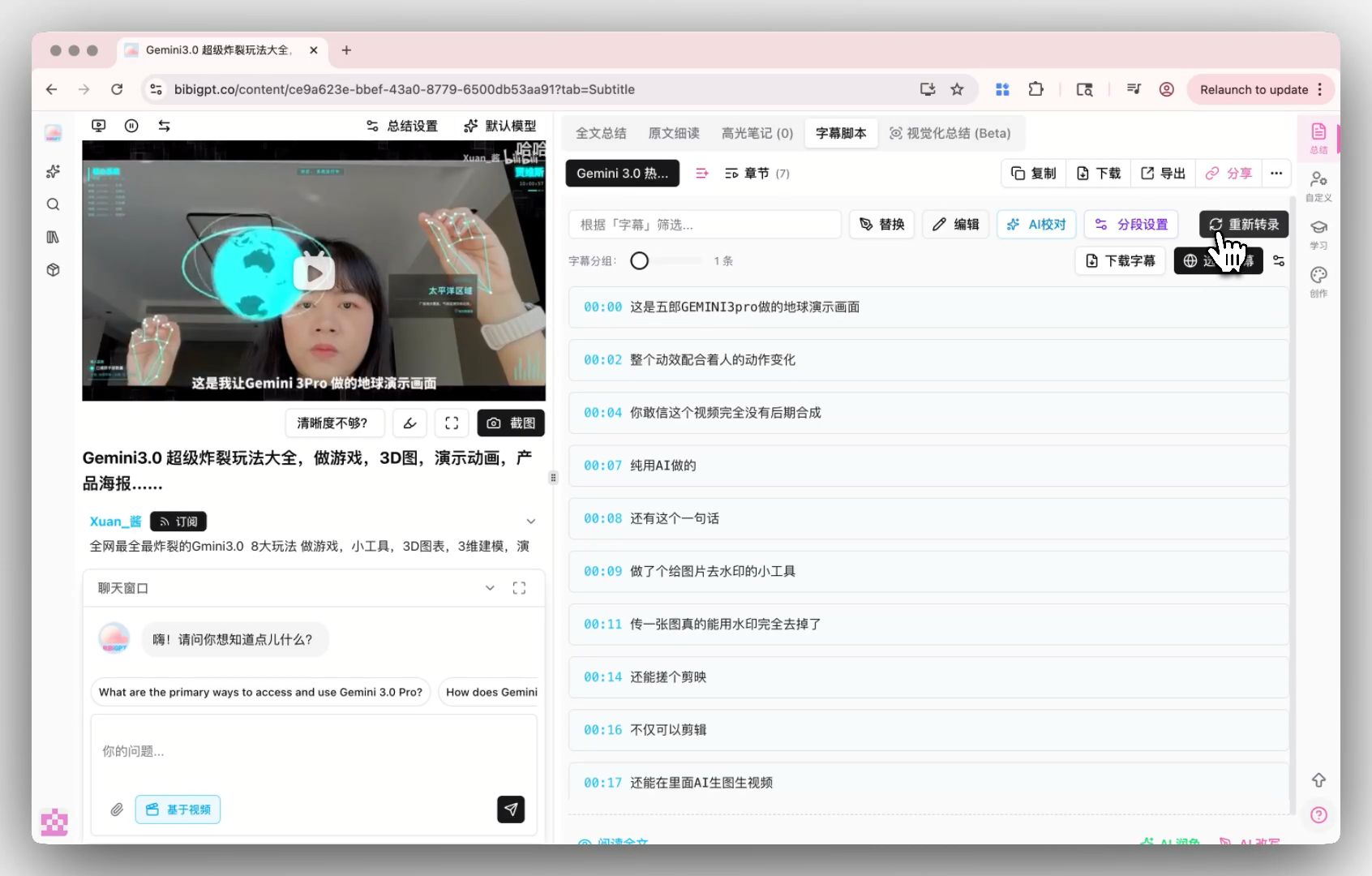
Custom transcription engine ของ BibiGPT ปัจจุบันรองรับ OpenAI Whisper และ ElevenLabs Scribe ที่เป็นผู้นำในวงการ MAI-Transcribe-1 ปัจจุบันใช้ได้เฉพาะ Azure / Copilot เมื่อ public APIs พัฒนาเต็มที่ BibiGPT จะประเมินการเพิ่มเข้า pool เพื่อให้ผู้ใช้สลับเอนจินจาก subtitle editor ได้ทันที
เส้นทางเสริม: MAI เป็นฐาน BibiGPT เป็นชั้น knowledge-artifact
แม้จะมี ASR ที่ดีที่สุด เอาต์พุตดิบยังเป็นแค่ข้อความ คุณค่าเฉพาะของ BibiGPT อยู่ปลายทางของ transcript:
- สรุปแบบมีโครงสร้าง + mind map — แยกระดับบทของเสียงยาว
- AI highlight notes — highlight ที่มี time-stamp ในคลิกเดียว
- Collection summary — สังเคราะห์หลายตอนเป็นแผนที่ความรู้
- การสร้างพอดแคสต์สองพิธีกร — สรุปกลายเป็นเสียงอีกครั้ง ปิด loop “พอดแคสต์ → พอดแคสต์”
สถาปัตยกรรม “สลับฐาน รักษาชั้นผลิตภัณฑ์” นี้คือสิ่งที่ทำให้ BibiGPT ดูดซับโมเดลเสียงที่ดีที่สุดเมื่อปรากฏ อ่านเพิ่ม: Microsoft Copilot vs สรุปวิดีโอ BibiGPT และมุมมองก่อนหน้าเรื่อง MAI-Transcribe-1 vs Cohere open-source ASR
FAQ
Q1: MAI-Transcribe-1 เป็น open source หรือไม่? Self-host ได้ไหม?
A: ไม่ MAI-Transcribe-1 ปัจจุบันเป็น commercial offering ผ่าน Azure / Copilot สำหรับ self-hosting ให้ใช้ OpenAI Whisper (MIT) หรือ Mistral Voxtral (Apache 2.0)
Q2: BibiGPT ใช้ MAI-Transcribe-1 เป็นค่า default หรือไม่?
A: ยัง BibiGPT ปัจจุบันใช้ pipeline แบบไฮบริดในเครือ + Whisper ผู้ใช้สามารถสลับไป ElevenLabs Scribe ใน custom transcription engine ได้ MAI-Transcribe-1 จะถูกประเมินเมื่อ public APIs พัฒนาเต็มที่
Q3: MAI-Voice-1 มีความหมายอย่างไรต่อครีเอเตอร์พอดแคสต์?
A: ครีเอเตอร์จะสามารถใช้ TTS เร็วอย่าง MAI-Voice-1 ในการย้อนกลับ transcript เป็นเสียงหลายพิธีกร การสร้างพอดแคสต์ ของ BibiGPT แปลงวิดีโอเป็นการสนทนาสองพิธีกรอยู่แล้ว TTS ที่เร็วขึ้นจะลด latency ลงไปอีก
Q4: MAI-Transcribe-1 ดีกว่า Whisper บนพอดแคสต์ภาษาจีนแค่ไหน?
A: Public benchmarks สำหรับภาษาจีนยังจำกัด ใช้ BibiGPT เพื่อรัน Whisper vs ElevenLabs Scribe เปรียบเทียบกันได้วันนี้ เมื่อ MAI-Transcribe-1 เปิด BibiGPT จะเผยแพร่การเปรียบเทียบเชิงปฏิบัติ
Q5: ทำไมไม่ตั้งทุกคนเป็น default ที่โมเดลแข็งแกร่งสุด?
A: โมเดลต่างกันมี trade-off ระหว่างต้นทุน ความแม่นยำ และการครอบคลุมภาษา การ hard-bind โมเดลเดียวจะตัดการควบคุมของผู้ใช้ในกรณีพิเศษ (ภาษาหายาก ศัพท์เฉพาะทาง) Custom transcription engine คืนการเลือกนั้นกลับไปสู่มือผู้ใช้
สรุป
MAI-Voice-1 + MAI-Transcribe-1 ของ Microsoft เป็นหมุดหมายของยุคใหม่ของโมเดลเสียงพื้นฐาน: in-house และ end-to-end low latency สำหรับเครื่องมือเสียงวิดีโอ AI นั่นคือการอัปเกรดทั้ง stack — การถอดเสียงที่แม่นยำขึ้น การสังเคราะห์ที่เร็วขึ้น เสียงยาวที่แข็งแกร่งขึ้น
ปรัชญาผลิตภัณฑ์ของ BibiGPT ไม่เคยล็อกกับโมเดลเสียงตัวเดียว — มันคือการเปลี่ยนฐานที่แข็งแกร่งใดๆ ให้เป็น knowledge artifact ที่หันเข้าหาผู้ใช้ เมื่อ MAI พัฒนาเต็มที่ BibiGPT จะเพิ่มเข้า pool custom transcription engine และยังคงส่งมอบสรุป AI ที่น่าเชื่อถือที่สุดสำหรับพอดแคสต์ วิดีโอข้ามพรมแดน และการเรียนรู้แบบยาว
เริ่มต้นการเรียนรู้ AI อย่างมีประสิทธิภาพของคุณตอนนี้:
- 🌐 เว็บไซต์ทางการ: https://aitodo.co
- 📱 ดาวน์โหลดบนมือถือ: https://aitodo.co/app
- 💻 ดาวน์โหลดบนเดสก์ท็อป: https://aitodo.co/download/desktop
- ✨ เรียนรู้ฟีเจอร์เพิ่มเติม: https://aitodo.co/features
BibiGPT Team