DeepSeek-V4 est là ! BibiGPT livre quatre nouveaux modèles + contexte 1M dès le premier jour — le résumé vidéo & podcast par IA passe au niveau supérieur
DeepSeek-V4 est là ! BibiGPT livre quatre nouveaux modèles + contexte 1M dès le premier jour — le résumé vidéo & podcast par IA passe au niveau supérieur
Aujourd’hui (24 avril 2026), DeepSeek-V4 Preview a été officiellement lancé et passé entièrement en open-source — 1M de contexte est désormais le défaut, et la capacité d’agent a comblé l’écart avec Sonnet 4.5. BibiGPT a complété l’intégration le jour même, et DeepSeek V4 Pro, V4 Pro Thinking, V4 Flash et V4 Flash Thinking sont désormais sélectionnables directement dans le sélecteur de modèle, prêts pour un documentaire long, un entretien de deux heures ou une saison complète de podcast.
Nous avons passé les modèles à travers quelques scénarios réels immédiatement. Cet article est une note pratique partagée en même temps, pour tous ceux qui travaillent avec ce type de contenu.
Sommaire
- Quoi de neuf dans DeepSeek-V4
- Les quatre modèles DeepSeek V4 désormais en ligne dans BibiGPT
- Basculer vers DeepSeek V4 en trois étapes
- Pratique : résumer la vidéo de lancement de DeepSeek avec V4 Pro
- Scénarios où basculer vers V4 s’applique directement
- L’ère de l’IA : ce qui est rare ce ne sont pas les modèles, mais la vitesse à laquelle vous consommez du contenu
- FAQ
Quoi de neuf dans DeepSeek-V4
DeepSeek-V4 fait bouger trois cadrans clés à la fois. Chacun mérite une note séparée.
Premièrement, 1M de contexte devient le défaut sur tous les services officiels DeepSeek. Le nouveau mécanisme d’attention compresse le long de la dimension token et se combine avec DSA (DeepSeek Sparse Attention) pour réduire le coût mémoire et calcul. Concrètement, alimenter une heure de sous-titres ne nécessite plus la routine « découper et recoller » — le modèle le lit comme un corps continu unique.
Deuxièmement, la capacité d’agent fait un net pas en avant. Selon la propre mesure de DeepSeek, V4-Pro mène tous les modèles open-source sur Agentic Coding et fournit une qualité proche d’Opus 4.6 non-thinking ; ils l’utilisent déjà comme modèle de codage interne par défaut. Pour les utilisateurs quotidiens, cela se traduit par une structuration de longs textes plus fiable — chapitrage, extraction de points clés, génération de cartes mentales — avec une stabilité nettement meilleure.
Troisièmement, Pro et Flash se complètent. Pro (1,6T params / 49B actifs / 33T tokens de pré-entraînement) cible les meilleurs modèles closed-source ; Flash (284B / 13B / 32T) est l’option économique. Tous deux supportent les modes thinking et non-thinking, et le mode thinking supporte le réglage reasoning_effort. Flash pour les tâches simples, Pro pour les lourdes — les deux paraissent solides.

L’annonce originale (en chinois) est ici : DeepSeek-V4 Preview : l’ère du million de tokens devient courante. Les poids du modèle sont disponibles dans la collection Hugging Face DeepSeek V4 (Pro / Pro-Base / Flash / Flash-Base, quatre dépôts) ; le rapport technique est dans DeepSeek_V4.pdf.
Les quatre modèles DeepSeek V4 désormais en ligne dans BibiGPT
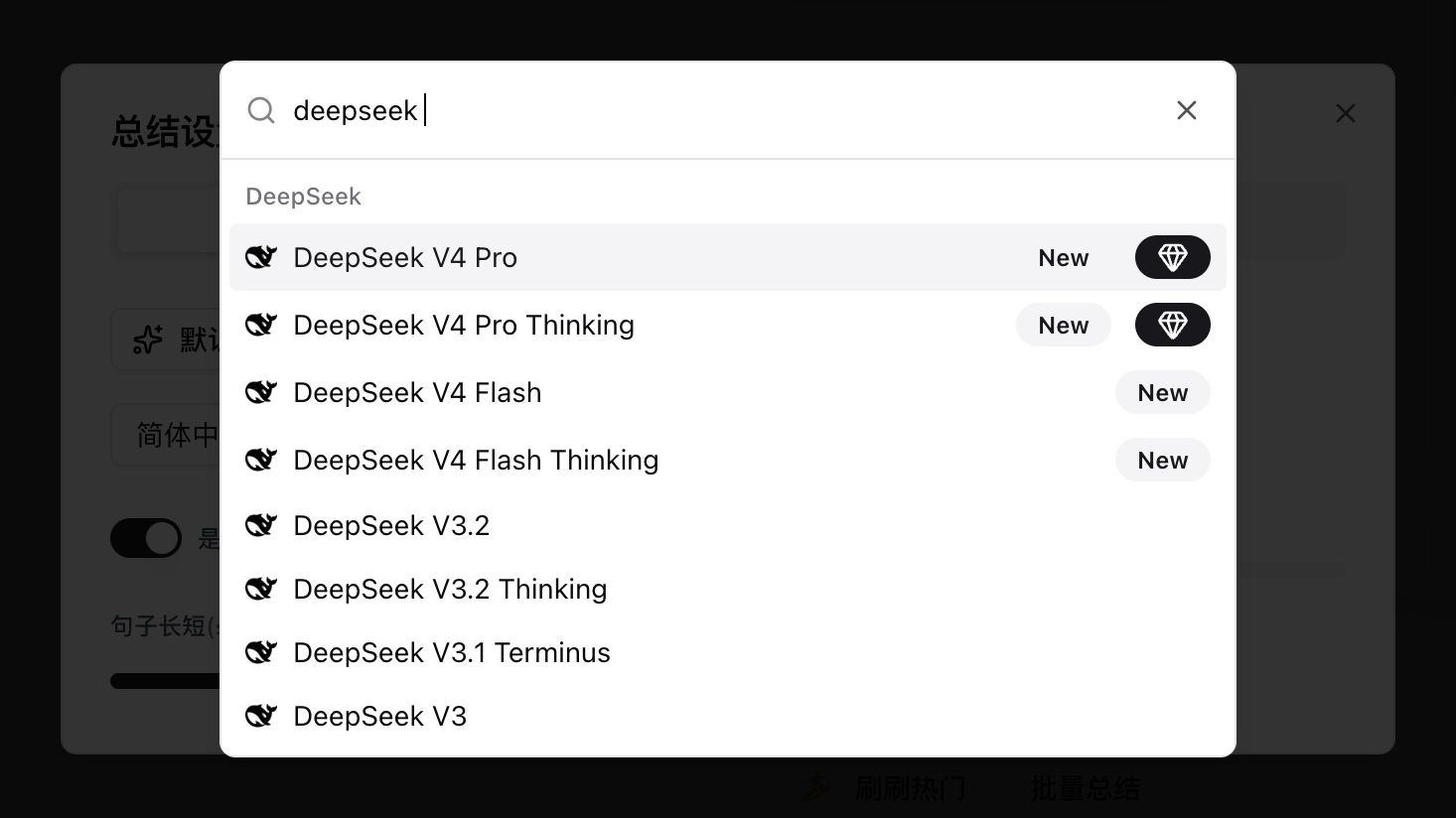
Ouvrez n’importe quels paramètres de résumé vidéo ou audio, tapez deepseek dans le sélecteur de modèle, et vous verrez quatre nouvelles entrées étiquetées New :
| Modèle | Cas d’usage | Thinking |
|---|---|---|
| DeepSeek V4 Pro | Qualité de premier plan pour contenu long et logique-intensive | Non-thinking |
| DeepSeek V4 Pro Thinking | V4 Pro avec raisonnement explicite — agent et analyse profonde | Thinking |
| DeepSeek V4 Flash | Économique, idéal pour contenu court et informel | Non-thinking |
| DeepSeek V4 Flash Thinking | Flash avec raisonnement, équilibrant vitesse et profondeur | Thinking |
Lequel choisir ? Une règle de décision simple :
- Contenu long (plus d’une heure, saisons complètes de podcast, longs entretiens) → Pro ou Pro Thinking pour un raisonnement plus profond sur l’ensemble
- Contenu court (moins de 30 minutes, réunions, vlogs quotidiens) → Flash, plus rapide et économique
- Vous voulez que le modèle raisonne pas à pas, compare les points de vue, approfondisse → choisissez une variante Thinking
- Juste besoin d’un résumé propre, sans trace de raisonnement → choisissez une variante non-thinking
Si vous ne voulez pas comparer minutieusement, commencez par V4 Pro Thinking — il livre des résultats cohérents sur la plupart des scénarios de contenu long.
Basculer vers DeepSeek V4 en trois étapes
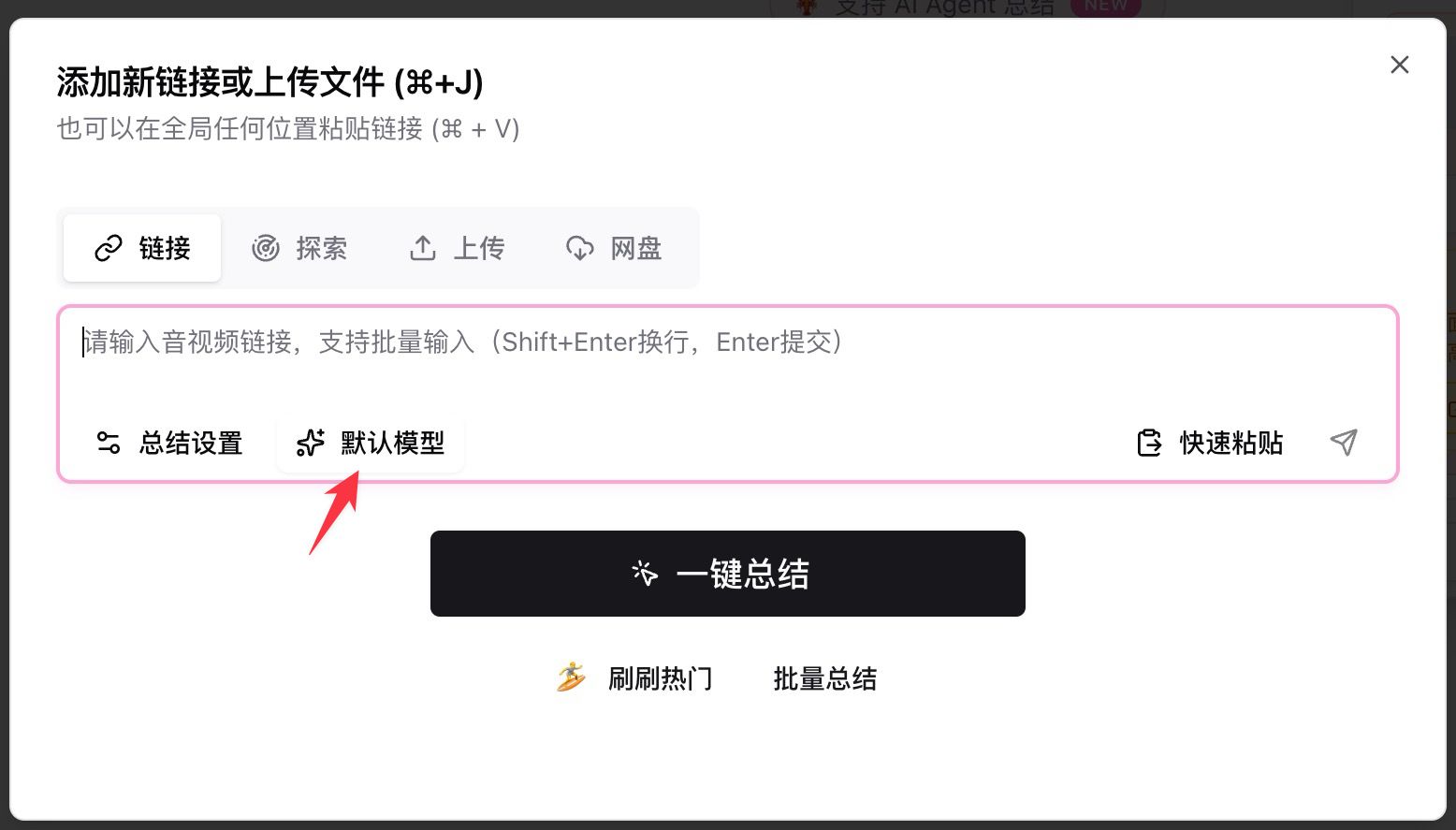
- Ouvrez BibiGPT, collez un lien YouTube / podcast / fichier local dans la zone de saisie
- Cliquez sur Default Model sous la zone de saisie, tapez
deepseekdans la barre de recherche - Choisissez l’une des quatre entrées New et cliquez sur le bouton de résumé
La sélection persiste à travers les sessions. Les utilisateurs avancés peuvent épingler V4 Pro Thinking comme résumé personnalisé par défaut, ainsi chaque vidéo future passera automatiquement par lui.
Vous voulez sentir la qualité de résumé de BibiGPT avant de changer de modèle ? Déposez n’importe quel lien dans le widget ci-dessous :
Pratique : résumer la vidéo de lancement de DeepSeek avec V4 Pro
La première chose que nous avons faite a été de passer V4 Pro sur la propre vidéo de lancement de DeepSeek. Elle dure environ une minute et demie, et avec le mode thinking activé, le modèle l’a divisée en sept chapitres structurés, chacun avec son propre résumé, points forts, réflexion et examen critique.
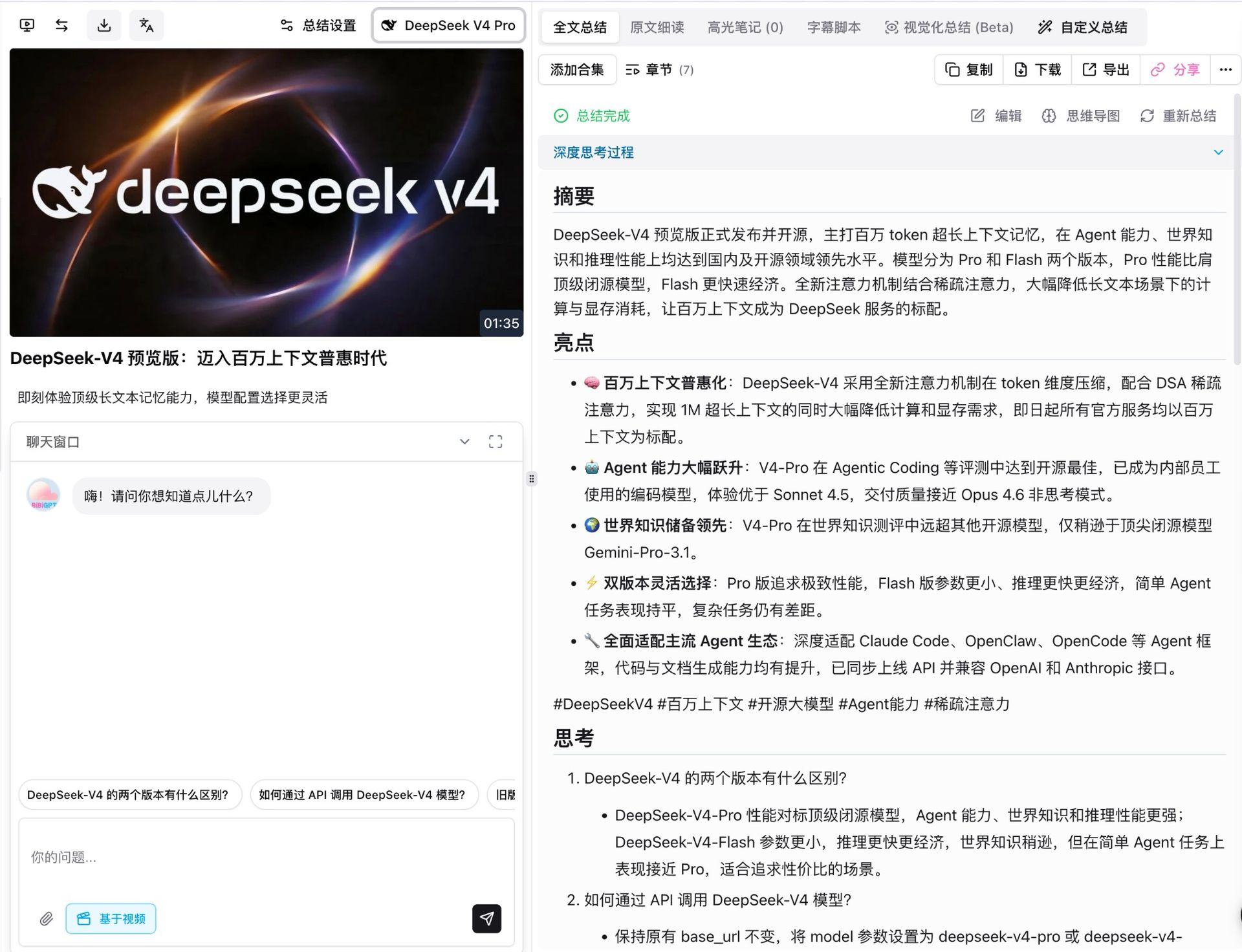
Quelques détails à souligner :
- Couverture factuelle complète : les cinq affirmations principales du communiqué (1M de contexte par défaut, saut d’agent, leadership en connaissance du monde, flexibilité à deux niveaux, compatibilité écosystème agent) sont passées correctement, y compris les chiffres des paramètres
- Chaque conclusion est traçable : chaque point renvoie à un horodatage cliquable de la vidéo, sautant directement au moment pertinent
- Les questions de suivi apparaissent automatiquement : sous le résumé, le modèle suggère des extensions comme « quelle est la différence entre les deux niveaux V4 » et « comment les appeler via l’API », prêts pour un approfondissement en un clic
L’amélioration ici vient principalement du raisonnement plus profond du mode thinking. Le contexte long est déjà un chemin par défaut sur les principaux modèles dans BibiGPT, et l’arrivée de V4 amène cette combinaison « raisonnement profond + stabilité de transcription complète » dans le palier open-source à une qualité de premier ordre.
Scénarios où basculer vers V4 s’applique directement
Les modèles open-source continuent d’apparaître. Vous pourriez demander : ne puis-je pas simplement utiliser le site DeepSeek ou l’API directement ? Pourquoi passer par BibiGPT ?
Cela revient au scénario. Le site DeepSeek est une boîte de chat générique — vous devez encore télécharger la vidéo, transcrire, coller, et trouver comment prompter. BibiGPT fait une chose depuis des années : rendre les longues vidéos et podcasts aussi faciles à consommer que la lecture d’un article. V4 est la dernière capacité ajoutée à cette pile ; ce qui fait vraiment fonctionner « collez un lien, obtenez une vraie compréhension » c’est la couche produit que nous affinons autour du modèle.
À l’intérieur de BibiGPT, les capacités suivantes suivent directement le modèle que vous sélectionnez comme votre « Default Model » — autrement dit, une fois que vous basculez vers DeepSeek V4, ces fonctionnalités tournent sur V4.
📝 Résumés vidéo (par défaut + prompt personnalisé)
Ce que vous utilisez le plus souvent — appuyer sur « Résumer » après avoir collé un lien — tourne sur le modèle que vous avez sélectionné. Tous les prompts personnalisés enregistrés (des choses comme « Analyste contre-intuitif », « Pensée critique » ou « Analyste en investissement ») passent par le même modèle. Basculez vers DeepSeek V4 Pro Thinking, relancez la même vidéo avec le même prompt, et obtenez une comparaison côte à côte directe sur la profondeur de raisonnement et la structure. C’est l’un des scénarios que nous explorons encore nous-mêmes — exécutez-le sur votre propre contenu et voyez si le résultat correspond mieux à vos attentes.
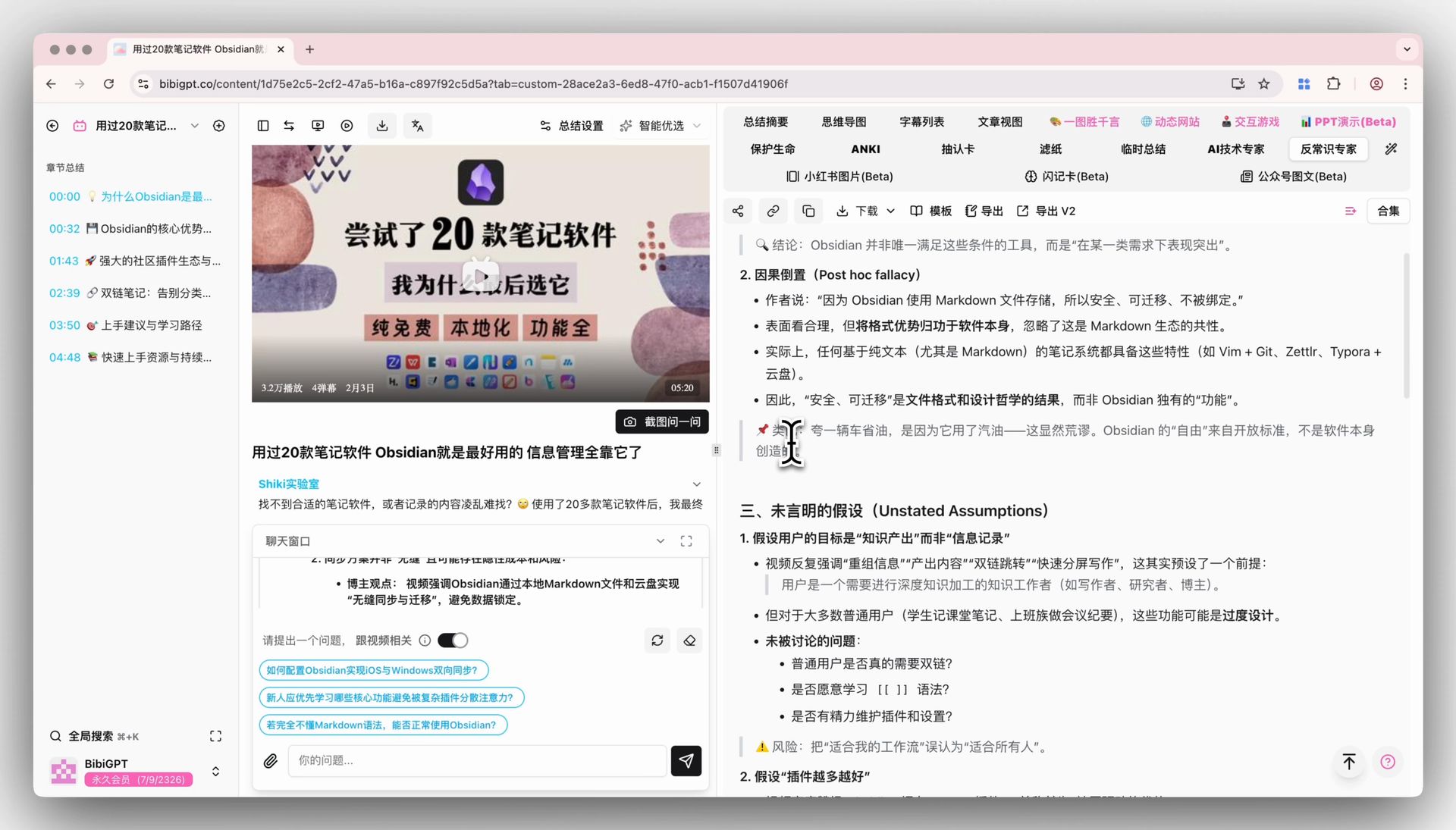
🎯 Chat vidéo IA avec traçage de source
La fenêtre de chat sous la page de détail vidéo suit aussi le modèle par défaut. Chaque réponse porte un horodatage cliquable — « il a fait l’argument inverse à 1:12:30 », un clic et vous y sautez. Une fois que vous avez basculé vers V4, choisissez un entretien de plus d’une heure et posez quelques tours de questions de suivi — c’est un scénario où les différences entre modèles ont tendance à apparaître rapidement, et qui mérite un essai de première main.
🔖 Notes IA des moments forts
Extraire les clips forts d’une vidéo avec horodatages — groupés par sujet — tourne aussi sur le modèle par défaut. Si vous avez déjà généré des notes de moments forts pour une vidéo sur un autre modèle, relancez-les sur V4 et comparez quels clips sont marqués comme forts et comment les sujets se groupent. Si la différence est significative sur votre contenu est plus facile à juger en le faisant vous-même.
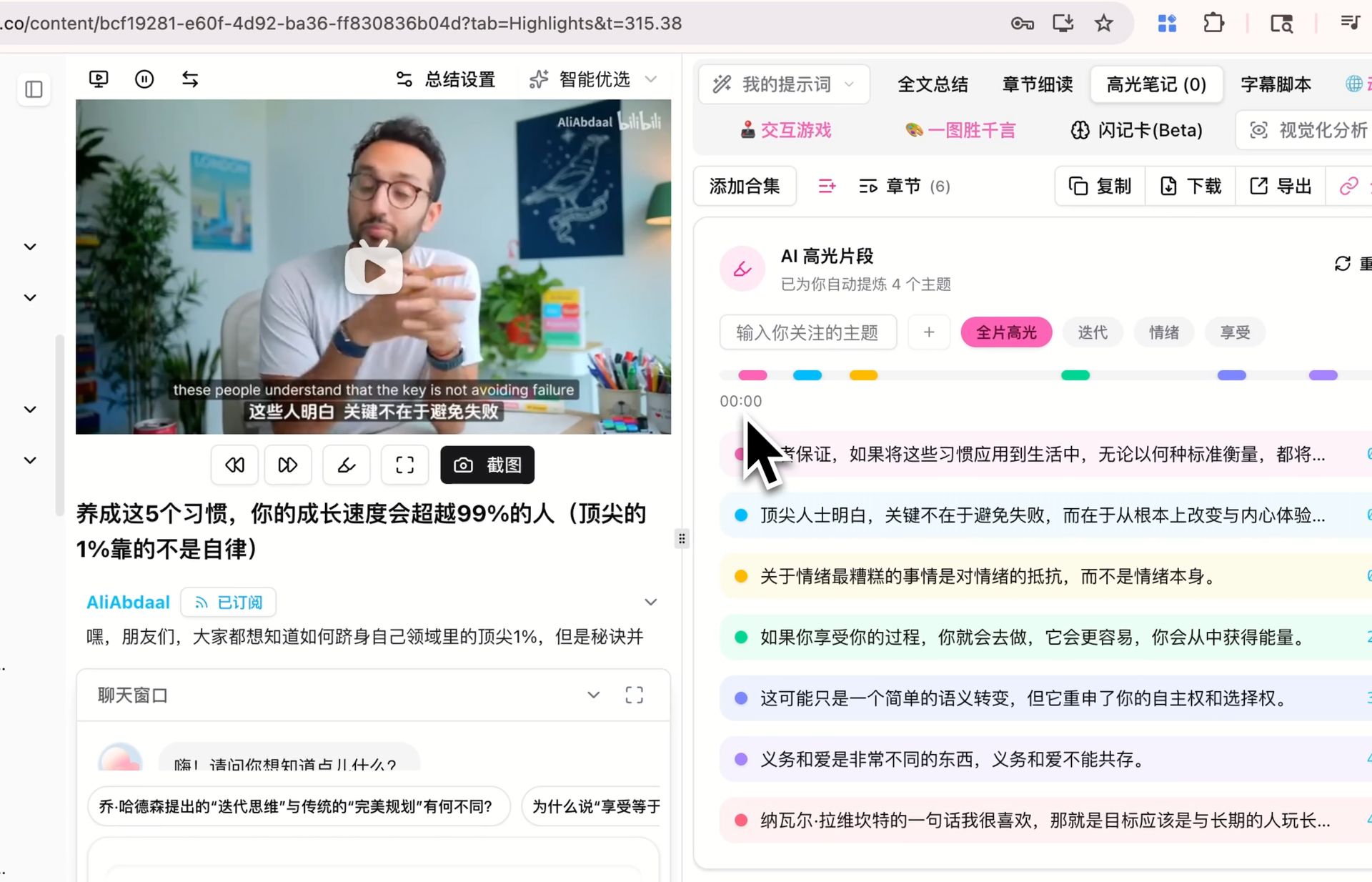
Les trois sont des scénarios que nous évaluons encore nous-mêmes — les résultats varient selon les contenus, les prompts et les langues, et l’avis le plus fiable est celui que vous formez après quelques essais dans votre propre workflow.
Quelques autres domaines utilisent des modèles dédiés — l’analyse de contenu visuel tourne sur un modèle de vision, et la vidéo-vers-article-illustré utilise un pipeline fixe — donc ils ne répondent pas au changement de modèle par défaut et ne font pas partie de la comparaison ci-dessus.
BibiGPT a servi 1M+ utilisateurs et généré 5M+ résumés IA à ce jour. Cette échelle nous aide à mapper rapidement chaque nouveau modèle sur des scénarios réels, plutôt que de rester à la couche de comparaison de benchmarks.
L’ère de l’IA : ce qui est rare ce ne sont pas les modèles, mais la vitesse à laquelle vous consommez du contenu
En 2026, les modèles d’IA sont essentiellement comme l’eau courante — DeepSeek V4, Gemini 3.1 Pro, Claude Opus 4.6 sont tous à portée. Les modèles ne sont plus rares.
Qu’est-ce qui est rare ? La vitesse à laquelle vous transformez l’information en opinions, et les opinions en action.
L’audio et la vidéo sont le format à la plus faible densité, le plus long à consommer sur internet. Un entretien de deux heures transcrit fait 8 000 mots, mais la vraie thèse pourrait en faire 300. Une saison de podcast de 30 heures donne peut-être 20 citations durables. Pendant des années, le seul truc était la lecture à 1,5x ou 2x — échanger l’attention contre la densité. Avec les derniers modèles, le calcul s’inverse :
- Plus d’écoute passive, posez juste les questions qui vous intéressent — le modèle tire les réponses de la transcription
- Pas besoin de finir avant de juger, lisez d’abord le résumé, puis décidez s’il mérite l’heure
- Plus de feuilletage une vidéo à la fois, cherchez à travers toutes — « qui parmi les 100 créateurs que je suis a parlé de ce sujet »
BibiGPT fait une chose : brancher le meilleur modèle disponible sur le format le plus grand mais le plus difficile à consommer — l’audio et la vidéo — pour que n’importe qui puisse compresser deux heures de vidéo en quinze minutes de lecture à haute densité. DeepSeek V4 ajoute une option fiable de plus à cette pile.
FAQ
Q1 : Quelle est la différence entre DeepSeek V4 Pro et V4 Pro Thinking ?
La différence centrale est si le raisonnement est explicite. Non-thinking a une latence plus faible avec une sortie plus courte, bon pour un résumé propre. Le mode thinking génère d’abord une chaîne de raisonnement — meilleur pour la logique multi-étapes, la comparaison inter-chapitres ou l’analyse d’arguments. Vous pouvez régler la profondeur avec reasoning_effort=high/max ; raisonnement plus profond, sortie plus lente.
Q2 : Devrais-je choisir V4 Pro ou V4 Flash ?
Pensez en termes de « longueur × complexité du raisonnement ». Plus d’une heure ou raisonnement multi-étapes → Pro. Moins de trente minutes et un résumé propre suffit → Flash. En cas de doute, commencez par Flash et passez à Pro s’il manque — BibiGPT met en cache la transcription donc re-résumer saute entièrement l’étape de transcription.
Q3 : Pourquoi passer par BibiGPT au lieu d’utiliser le site DeepSeek directement ?
Le site DeepSeek est une boîte de chat générique — vous devez encore télécharger, transcrire, coller et prompter vous-même. BibiGPT gère le pipeline en amont (parsing de liens 30+ plateformes, transcription, analyse visuelle, alignement d’horodatages), et DeepSeek V4 n’a qu’à couvrir l’étape finale comprendre-et-générer. Même entrée, et vous obtenez en plus des cartes mentales, des notes de moments forts, des articles illustrés et des exports structurés sans aucun assemblage supplémentaire.
Q4 : Quelle longueur de vidéo DeepSeek V4 peut-il gérer ?
V4 Pro et Flash ont tous deux 1M de contexte token — environ 1,5 million de caractères chinois, ou plus de 20 heures de dialogue — assez pour une saison complète de podcast. BibiGPT décide automatiquement entre la résumarisation en une passe et chunk-puis-consolider en fonction du contexte effectif du modèle.
Q5 : Les poids de DeepSeek V4 sont-ils open-source ?
Entièrement open-source. Les poids sont sur Hugging Face deepseek-ai/deepseek-v4 et ModelScope ; le rapport technique est dans DeepSeek_V4.pdf. Les chercheurs et auto-hébergeurs peuvent les récupérer directement.
Essayez V4 maintenant
Le moyen le plus direct de sentir V4 : choisissez une longue vidéo que vous vouliez vraiment regarder — un cours, un épisode de podcast, un documentaire, peu importe — et faites-la passer par DeepSeek V4 Pro Thinking. Voyez comment V4 gère quelque chose qui vous tient vraiment à cœur.
Commencez votre parcours d’apprentissage IA efficace maintenant :
- 🌐 Site officiel : https://aitodo.co
- 📱 Téléchargement mobile : https://aitodo.co/app
- 💻 Téléchargement desktop : https://aitodo.co/download/desktop
- ✨ Découvrir plus de fonctionnalités : https://aitodo.co/features
BibiGPT Team