DeepSeek-V4 ist da! BibiGPT liefert vier neue Modelle + 1M Kontext am ersten Tag — KI-Video- und Podcast-Zusammenfassung neu definiert
DeepSeek-V4 ist da! BibiGPT liefert vier neue Modelle + 1M Kontext am ersten Tag — KI-Video- und Podcast-Zusammenfassung neu definiert
Heute (24. April 2026) wurde DeepSeek-V4 Preview offiziell veröffentlicht und vollständig Open Source — 1M Kontext ist jetzt Standard, und die Agent-Fähigkeit hat die Lücke zu Sonnet 4.5 geschlossen. BibiGPT hat die Integration am selben Tag abgeschlossen, und DeepSeek V4 Pro, V4 Pro Thinking, V4 Flash und V4 Flash Thinking sind jetzt direkt im Modellauswähler wählbar, bereit für eine Dokumentation in voller Länge, ein zweistündiges Interview oder eine ganze Podcast-Saison.
Wir haben die Modelle sofort durch einige reale Szenarien laufen lassen. Dieser Beitrag ist eine zeitgleich geteilte Praxisnotiz für alle, die mit der gleichen Art von Inhalten arbeiten.
Inhaltsverzeichnis
- Was ist neu in DeepSeek-V4
- Die vier DeepSeek V4 Modelle jetzt live in BibiGPT
- In drei Schritten zu DeepSeek V4 wechseln
- Praxistest: DeepSeeks eigenes Launch-Video mit V4 Pro zusammenfassen
- Szenarien, in denen der Wechsel zu V4 direkt anwendbar ist
- Die KI-Ära: knapp sind nicht Modelle, sondern wie schnell Sie Inhalte konsumieren
- FAQ
Was ist neu in DeepSeek-V4
DeepSeek-V4 dreht drei wichtige Stellschrauben gleichzeitig. Jede verdient eine eigene Notiz.
Erstens: 1M Kontext wird Standard in DeepSeeks offiziellen Diensten. Der neue Aufmerksamkeitsmechanismus komprimiert entlang der Token-Dimension und kombiniert sich mit DSA (DeepSeek Sparse Attention), um Speicher- und Rechenkosten zu senken. Praktisch heißt das: Eine Stunde Untertitel einzuspeisen erfordert nicht länger die „Chunk-and-Stitch”-Routine — das Modell liest sie als einen kontinuierlichen Körper.
Zweitens: Die Agent-Fähigkeit macht einen klaren Sprung. Nach DeepSeeks eigener Messung führt V4-Pro alle Open-Source-Modelle bei Agentic Coding an und liefert Qualität nahe Opus 4.6 ohne Thinking; sie nutzen es bereits als Standard-internes Coding-Modell. Für alltägliche Nutzer übersetzt sich das in zuverlässigere Strukturierung langer Texte — Kapiteleinteilung, Schlüsselpunkt-Extraktion, Mindmap-Generierung — mit deutlich besserer Stabilität.
Drittens: Pro und Flash ergänzen sich. Pro (1,6T Parameter / 49B aktiv / 33T Pre-Training-Tokens) zielt auf Top-Closed-Source-Modelle; Flash (284B / 13B / 32T) ist die kosteneffiziente Option. Beide unterstützen Thinking- und Non-Thinking-Modi, und der Thinking-Modus unterstützt reasoning_effort-Tuning. Flash für einfache Aufgaben, Pro für schwere — beide fühlen sich solide an.

Die ursprüngliche Ankündigung (auf Chinesisch) ist hier: DeepSeek-V4 Preview: Die Million-Token-Ära wird Mainstream. Modellgewichte sind in der Hugging Face DeepSeek V4 Sammlung verfügbar (Pro / Pro-Base / Flash / Flash-Base, vier Repos); der technische Bericht ist in DeepSeek_V4.pdf.
Die vier DeepSeek V4 Modelle jetzt live in BibiGPT
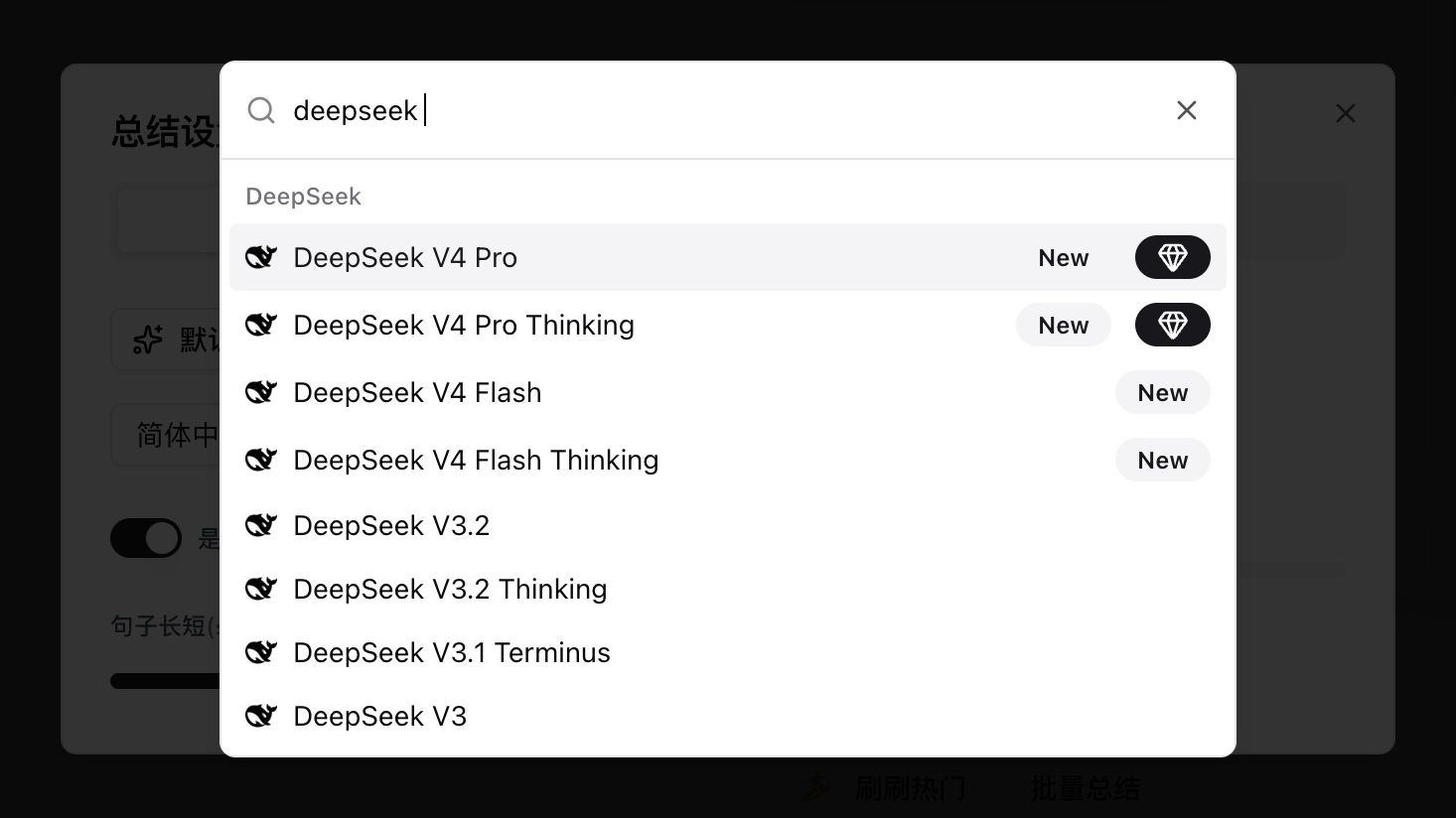
Öffnen Sie eine beliebige Video- oder Audio-Zusammenfassungseinstellung, tippen Sie deepseek im Modellauswähler, und Sie sehen vier neue Einträge mit dem Tag New:
| Modell | Anwendungsfall | Thinking |
|---|---|---|
| DeepSeek V4 Pro | Spitzenqualität für lange, logiklastige Inhalte | Non-Thinking |
| DeepSeek V4 Pro Thinking | V4 Pro mit explizitem Reasoning — Agent und Tiefenanalyse | Thinking |
| DeepSeek V4 Flash | Kosteneffizient, ideal für kurze und zwanglose Inhalte | Non-Thinking |
| DeepSeek V4 Flash Thinking | Flash mit Reasoning, balanciert Geschwindigkeit und Tiefe | Thinking |
Welches wählen? Eine einfache Entscheidungsregel:
- Längere Inhalte (über eine Stunde, ganze Podcast-Saisons, lange Interviews) → Pro oder Pro Thinking für tieferes Reasoning über das gesamte Stück
- Kürzere Inhalte (unter 30 Minuten, Meetings, tägliche Vlogs) → Flash, schneller und ökonomischer
- Möchten Sie, dass das Modell schrittweise schlussfolgert, Standpunkte vergleicht, in die Tiefe geht → wählen Sie eine Thinking-Variante
- Brauchen Sie nur eine saubere Zusammenfassung, keine Reasoning-Spur → wählen Sie eine Non-Thinking-Variante
Wenn Sie nicht sorgfältig vergleichen möchten, beginnen Sie mit V4 Pro Thinking — es liefert konsistente Ergebnisse über die meisten Langinhalts-Szenarien.
In drei Schritten zu DeepSeek V4 wechseln
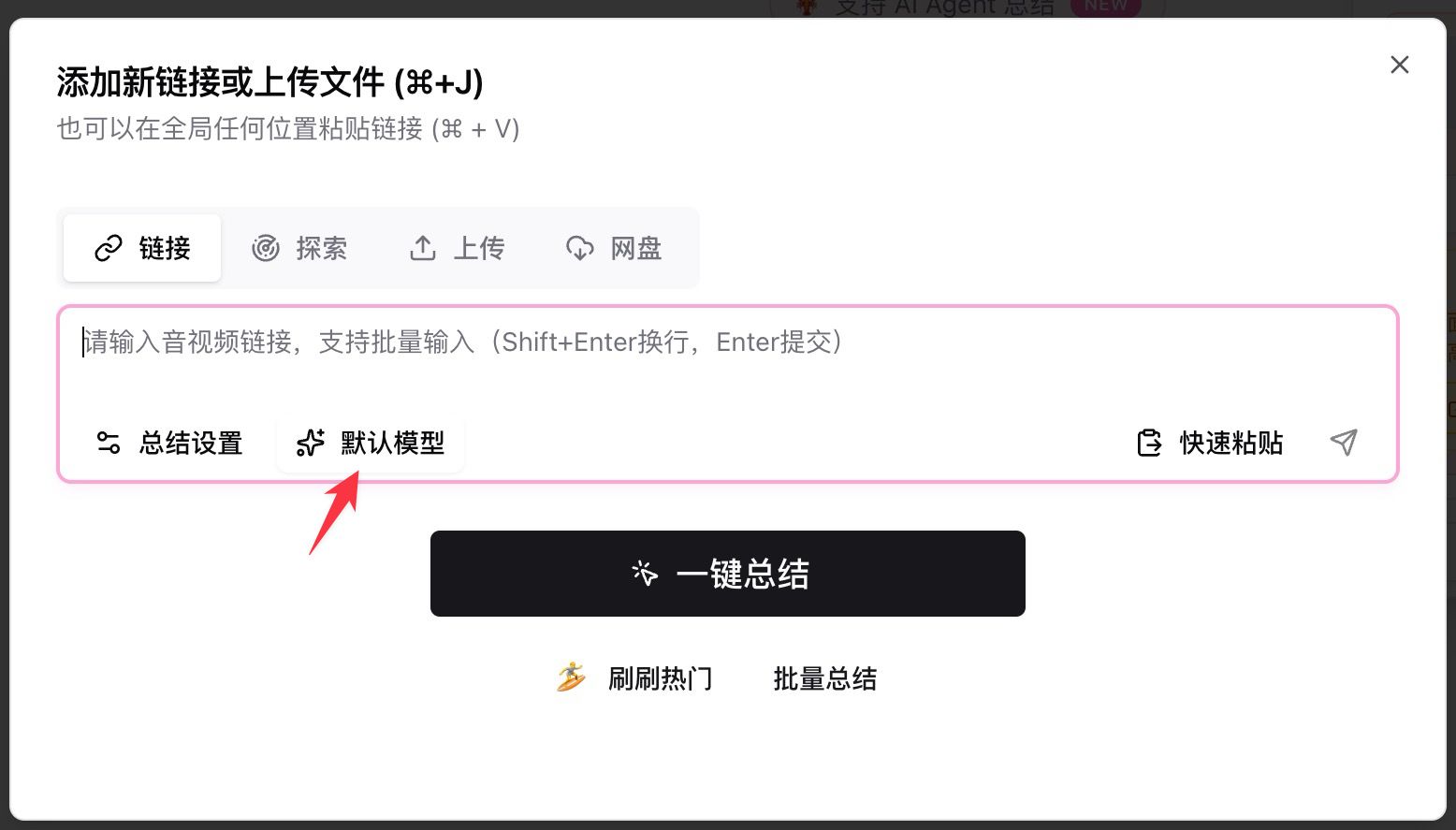
- BibiGPT öffnen, einen YouTube- / Podcast- / lokalen Datei-Link in das Eingabefeld einfügen
- Auf Standardmodell unter der Eingabe klicken,
deepseekin die Suchleiste tippen - Einen der vier New-Einträge wählen und auf den Zusammenfassen-Knopf drücken
Die Auswahl bleibt über Sitzungen erhalten. Power-User können V4 Pro Thinking als Standard-Custom-Summary anpinnen, sodass jedes zukünftige Video automatisch dadurch läuft.
Möchten Sie BibiGPTs Zusammenfassungsqualität spüren, bevor Sie Modelle wechseln? Werfen Sie einen beliebigen Link in das Widget unten:
Praxistest: DeepSeeks eigenes Launch-Video mit V4 Pro zusammenfassen
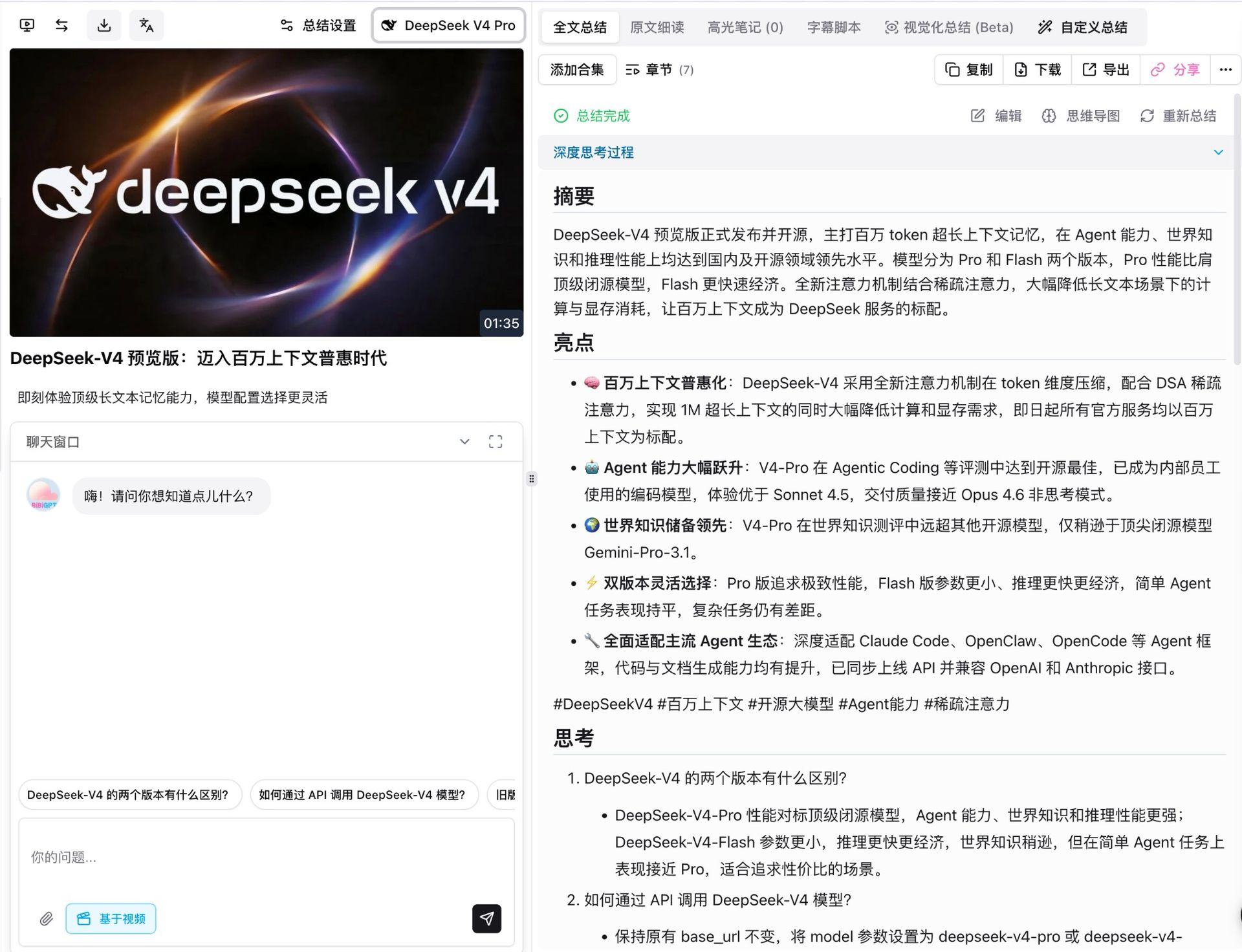
Das Erste, was wir taten, war V4 Pro auf DeepSeeks eigenem Launch-Video laufen zu lassen. Es ist etwa anderthalb Minuten lang, und mit aktiviertem Thinking-Modus teilte das Modell es in sieben strukturierte Kapitel auf, jedes mit eigener Zusammenfassung, Highlights, Reflexion und kritischer Überprüfung.
Einige Details, die hervorzuheben sind:
- Vollständige Faktenabdeckung: Alle fünf Kernaussagen aus der Veröffentlichung (1M Kontext als Standard, Agent-Sprung, Weltwissens-Vorsprung, Dual-Tier-Flexibilität, Agent-Ökosystem-Kompatibilität) kamen genau durch, einschließlich der Parameterzahlen
- Jede Schlussfolgerung ist nachverfolgbar: Jeder Punkt verlinkt zurück zu einem klickbaren Video-Zeitstempel und springt direkt zum relevanten Moment
- Folgefragen erscheinen automatisch: Unter der Zusammenfassung schlägt das Modell Erweiterungen vor wie „was ist der Unterschied zwischen den beiden V4-Stufen” und „wie rufe ich sie über die API auf”, bereit für einen Ein-Tipp-Tieftauchgang
Die Verbesserung kommt hier hauptsächlich aus dem tieferen Reasoning des Thinking-Modus. Langer Kontext ist bereits ein Standardpfad in den großen Modellen in BibiGPT, und V4s Ankunft bringt diese Kombination aus „tiefem Reasoning + Voll-Transkript-Stabilität” in die Open-Source-Stufe in erstklassiger Qualität.
Szenarien, in denen der Wechsel zu V4 direkt anwendbar ist
Open-Source-Modelle erscheinen weiter. Sie könnten fragen: Kann ich nicht einfach die DeepSeek-Website oder die API direkt nutzen? Warum über BibiGPT gehen?
Es kommt auf das Szenario an. Die DeepSeek-Website ist eine generische Chatbox — Sie müssen das Video noch herunterladen, transkribieren, einfügen und herausfinden, wie zu prompten ist. BibiGPT macht seit Jahren eine Sache: lange Videos und Podcasts so leicht konsumierbar machen wie das Lesen eines Artikels. V4 ist die neueste Fähigkeit, die diesem Stack hinzugefügt wird; was tatsächlich „Link einfügen, echtes Verständnis erhalten” zum Funktionieren bringt, ist die Produktebene, die wir um das Modell herum verfeinert haben.
Innerhalb von BibiGPT folgen die folgenden Fähigkeiten direkt dem Modell, das Sie als Ihr „Standardmodell” auswählen — mit anderen Worten, sobald Sie zu DeepSeek V4 wechseln, laufen diese Funktionen auf V4.
📝 Video-Zusammenfassungen (Standard + Custom Prompt)
Das, was Sie am häufigsten verwenden — auf „Zusammenfassen” zu drücken, nachdem Sie einen Link eingefügt haben — läuft auf dem von Ihnen ausgewählten Modell. Alle gespeicherten benutzerdefinierten Prompts (Dinge wie „Counterintuitive Analyst”, „Critical Thinking” oder „Investment Analyst”) gehen ebenfalls durch dasselbe Modell. Wechseln Sie zu DeepSeek V4 Pro Thinking, lassen Sie dasselbe Video mit dem gleichen Prompt erneut laufen, und Sie erhalten einen direkten Side-by-Side-Vergleich zu Reasoning-Tiefe und Struktur. Das ist eines der Szenarien, die wir selbst noch erkunden — lassen Sie es auf Ihren eigenen Inhalten laufen und sehen Sie, ob das Ergebnis Ihren Erwartungen besser entspricht.
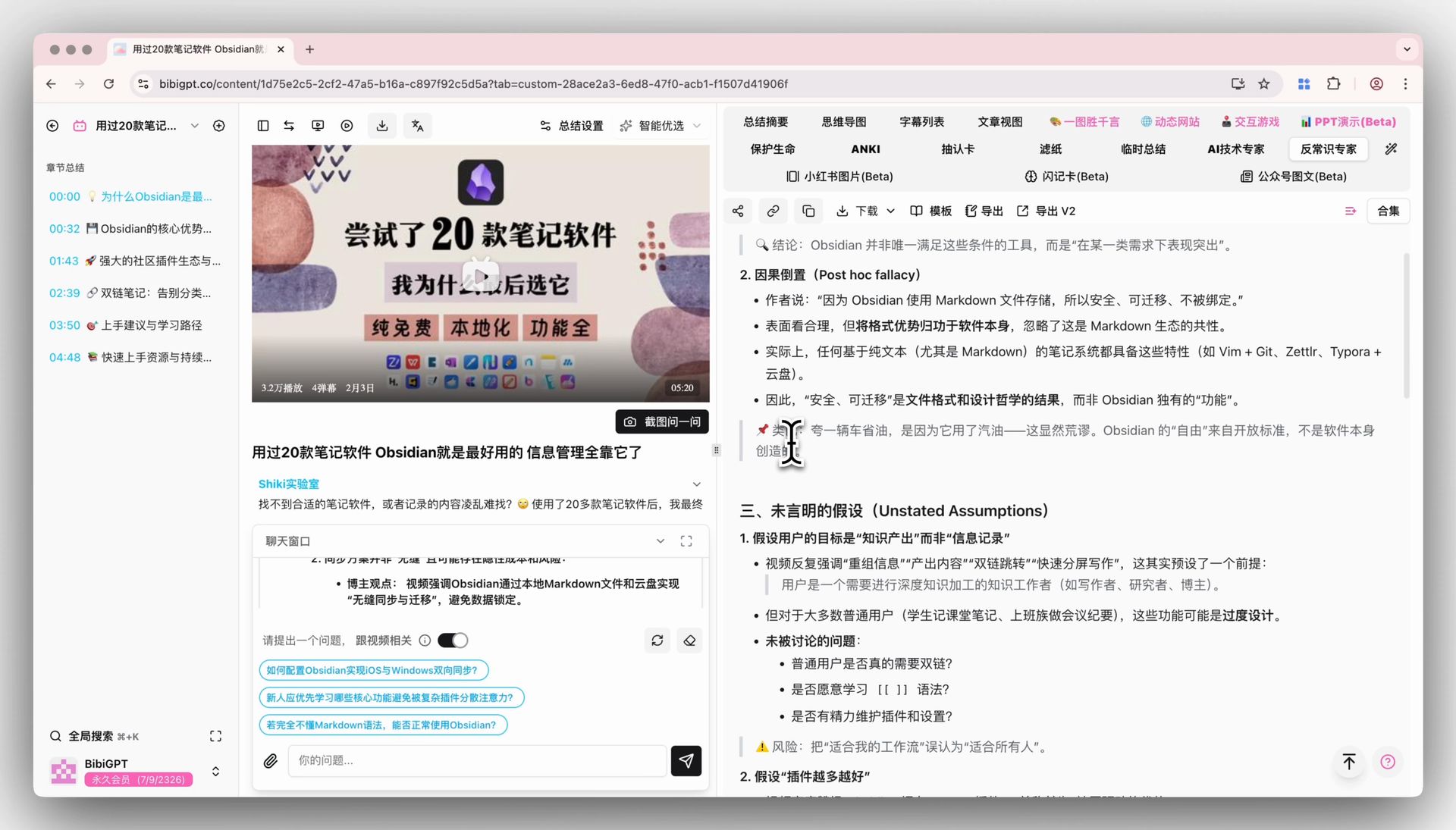
🎯 KI-Video-Chat mit Quellennachverfolgung
Das Chat-Fenster unter der Video-Detailseite folgt ebenfalls dem Standardmodell. Jede Antwort trägt einen klickbaren Zeitstempel — „er hat bei 1:12:30 das Gegenteil gesagt”, ein Tippen und Sie springen dorthin. Sobald Sie auf V4 gewechselt sind, wählen Sie ein Interview von 1+ Stunden und stellen einige Runden Folgefragen — das ist ein Szenario, in dem Unterschiede zwischen Modellen tendenziell schnell sichtbar werden, und es lohnt sich, es selbst auszuprobieren.
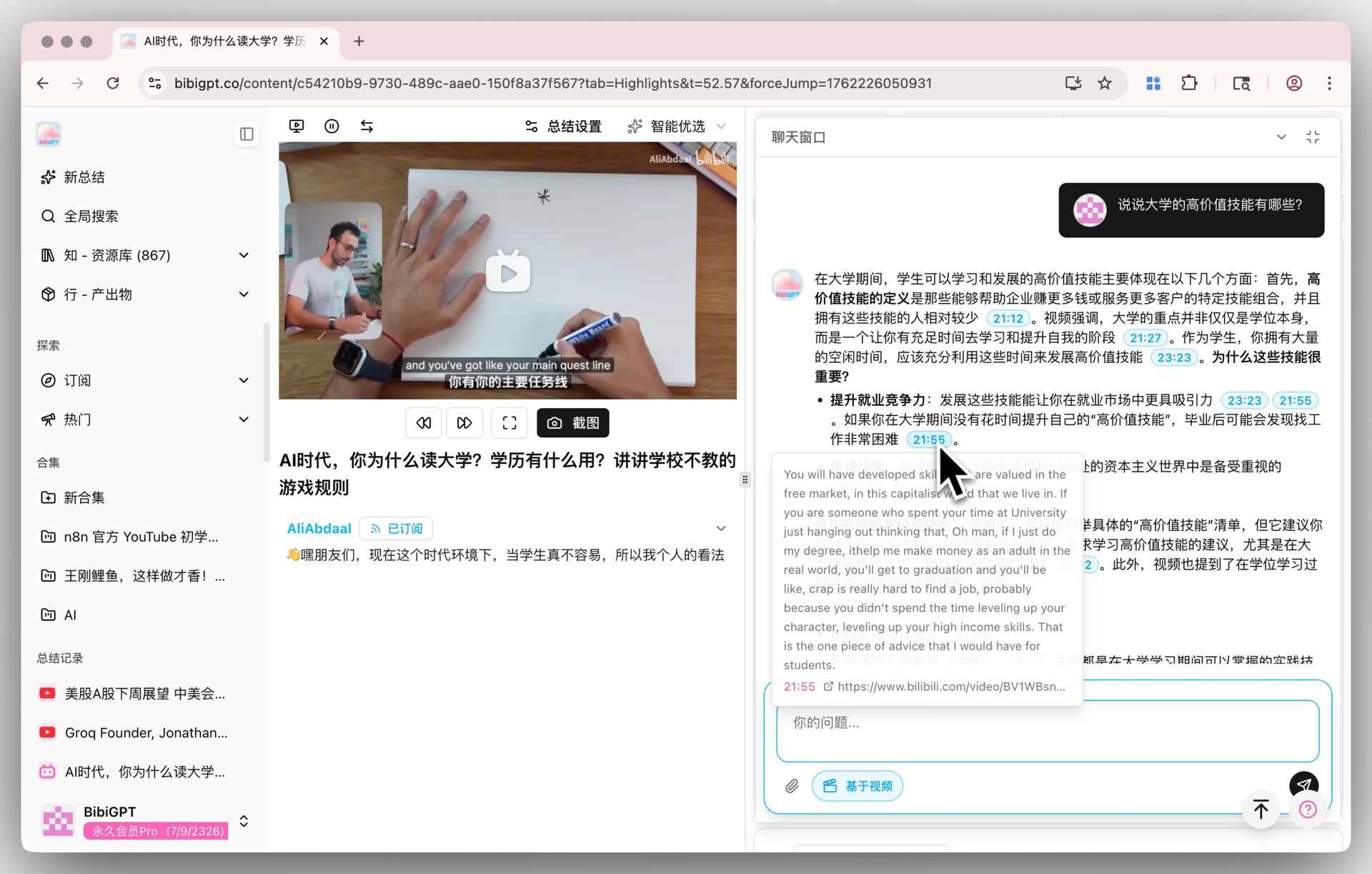
🔖 KI-Highlight-Notizen
Highlight-Clips aus einem Video mit Zeitstempeln zu extrahieren — gruppiert nach Thema — läuft ebenfalls auf dem Standardmodell. Wenn Sie für ein Video bereits Highlight-Notizen auf einem anderen Modell generiert haben, lassen Sie sie auf V4 erneut laufen und vergleichen Sie, welche Clips als Highlights markiert werden und wie die Themen geclustert sind. Ob der Unterschied bei Ihren Inhalten bedeutsam ist, lässt sich am einfachsten beurteilen, wenn Sie es selbst tun.
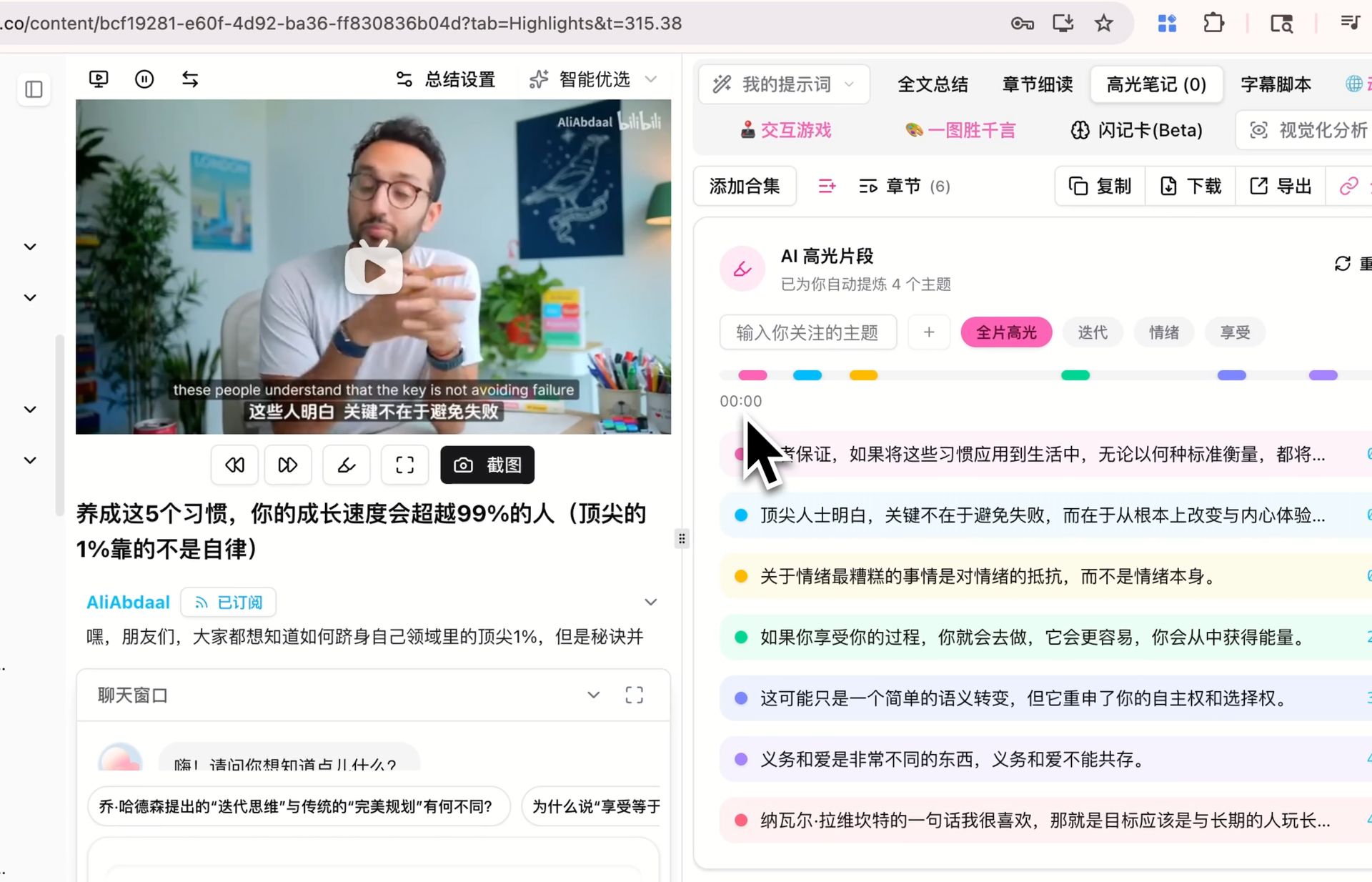
Alle drei sind Szenarien, die wir selbst noch evaluieren — Ergebnisse variieren über verschiedene Inhalte, Prompts und Sprachen, und die zuverlässigste Einschätzung ist diejenige, die Sie nach einigen Durchläufen innerhalb Ihres eigenen Workflows bilden.
Ein paar andere Bereiche verwenden dedizierte Modelle — die visuelle Inhaltsanalyse läuft auf einem Vision-Modell, und Video-zu-illustriertem-Artikel verwendet eine feste Pipeline — sodass sie nicht auf den Standardmodell-Wechsel reagieren und nicht Teil des obigen Vergleichs sind.
BibiGPT hat bisher 1M+ Nutzer bedient und 5M+ KI-Zusammenfassungen generiert. Diese Skala hilft uns, jedes neue Modell schnell auf reale Szenarien abzubilden, anstatt auf der Benchmark-Vergleichs-Ebene zu bleiben.
Die KI-Ära: knapp sind nicht Modelle, sondern wie schnell Sie Inhalte konsumieren
Im Jahr 2026 sind KI-Modelle im Wesentlichen wie fließendes Wasser — DeepSeek V4, Gemini 3.1 Pro, Claude Opus 4.6 sind alle in Reichweite. Modelle sind nicht länger knapp.
Was ist knapp? Wie schnell Sie Informationen in Meinungen verwandeln und Meinungen in Aktion.
Audio und Video sind das Format mit der niedrigsten Dichte und der längsten Konsumdauer im Internet. Ein zweistündiges Interview transkribiert sind 8.000 Wörter, aber die eigentliche These könnte 300 sein. Eine 30-stündige Podcast-Saison ergibt vielleicht 20 dauerhafte Zitate. Jahrelang war der einzige Trick die 1,5- oder 2-fache Wiedergabegeschwindigkeit — Aufmerksamkeit gegen Dichte tauschen. Mit den neuesten Modellen kippt die Mathematik:
- Kein passives Hören mehr, stellen Sie einfach die Fragen, die Sie interessieren — das Modell zieht die Antworten aus dem Transkript
- Nicht zu Ende sehen, bevor Sie urteilen, lesen Sie zuerst die Zusammenfassung, dann entscheiden Sie, ob es die Stunde wert ist
- Nicht mehr ein Video nach dem anderen durchblättern, suchen Sie über alle hinweg — „wer von den 100 Creatorn, denen ich folge, hat über dieses Thema gesprochen”
BibiGPT macht eine Sache: das beste verfügbare Modell in das größte, aber am schwersten zu konsumierende Format einzustöpseln — Audio und Video — sodass jeder zwei Stunden Video in fünfzehn Minuten dichte Lektüre komprimieren kann. DeepSeek V4 fügt dem Stack eine weitere zuverlässige Option hinzu.
FAQ
Q1: Was ist der Unterschied zwischen DeepSeek V4 Pro und V4 Pro Thinking?
Der Kernunterschied ist, ob das Reasoning explizit ist. Non-Thinking hat geringere Latenz mit kürzerer Ausgabe, gut für eine saubere Zusammenfassung. Thinking-Modus generiert zuerst eine Reasoning-Kette — besser für mehrstufige Logik, kapitelübergreifenden Vergleich oder Argumentanalyse. Sie können die Tiefe mit reasoning_effort=high/max einstellen; tieferes Reasoning, langsamere Ausgabe.
Q2: Soll ich V4 Pro oder V4 Flash wählen?
Denken Sie in Bezug auf „Länge × Reasoning-Komplexität”. Über eine Stunde oder mehrstufiges Reasoning → Pro. Unter dreißig Minuten und eine saubere Zusammenfassung reicht → Flash. Im Zweifel mit Flash beginnen und auf Pro wechseln, wenn es nicht reicht — BibiGPT cacht das Transkript, sodass das erneute Zusammenfassen den Transkriptionsschritt komplett überspringt.
Q3: Warum über BibiGPT gehen, statt die DeepSeek-Website direkt zu nutzen?
Die DeepSeek-Website ist eine generische Chatbox — Sie müssen noch herunterladen, transkribieren, einfügen und selbst prompten. BibiGPT übernimmt die vorgelagerte Pipeline (Link-Parsing für 30+ Plattformen, Transkription, visuelle Analyse, Zeitstempel-Ausrichtung), und DeepSeek V4 muss nur den abschließenden Verstehen-und-Generieren-Schritt abdecken. Gleiche Eingabe, und Sie erhalten zusätzlich Mindmaps, Highlight-Notizen, illustrierte Artikel und strukturierte Exporte ohne zusätzliche Montage.
Q4: Wie langes Video kann DeepSeek V4 verarbeiten?
V4 Pro und Flash haben beide 1M Token Kontext — etwa 1,5 Millionen chinesische Zeichen oder über 20 Stunden Dialog — genug für eine ganze Podcast-Saison. BibiGPT entscheidet automatisch zwischen Single-Pass-Zusammenfassung und Chunk-then-Consolidate basierend auf dem effektiven Kontext des Modells.
Q5: Sind die DeepSeek V4 Gewichte Open Source?
Vollständig Open Source. Gewichte sind auf Hugging Face deepseek-ai/deepseek-v4 und ModelScope; der technische Bericht ist in DeepSeek_V4.pdf. Forscher und Self-Hoster können sie direkt holen.
Probieren Sie V4 jetzt
Der direkteste Weg, V4 zu spüren: Wählen Sie ein langes Video, das Sie schon lange tatsächlich anschauen wollten — eine Vorlesung, eine Podcast-Episode, eine Dokumentation, was auch immer — und lassen Sie es durch DeepSeek V4 Pro Thinking laufen. Sehen Sie, wie V4 etwas verarbeitet, das Sie wirklich interessiert.
Starten Sie jetzt Ihre KI-Effizienzlernreise:
- 🌐 Offizielle Website: https://aitodo.co
- 📱 Mobile Download: https://aitodo.co/app
- 💻 Desktop Download: https://aitodo.co/download/desktop
- ✨ Mehr Funktionen entdecken: https://aitodo.co/features
BibiGPT Team